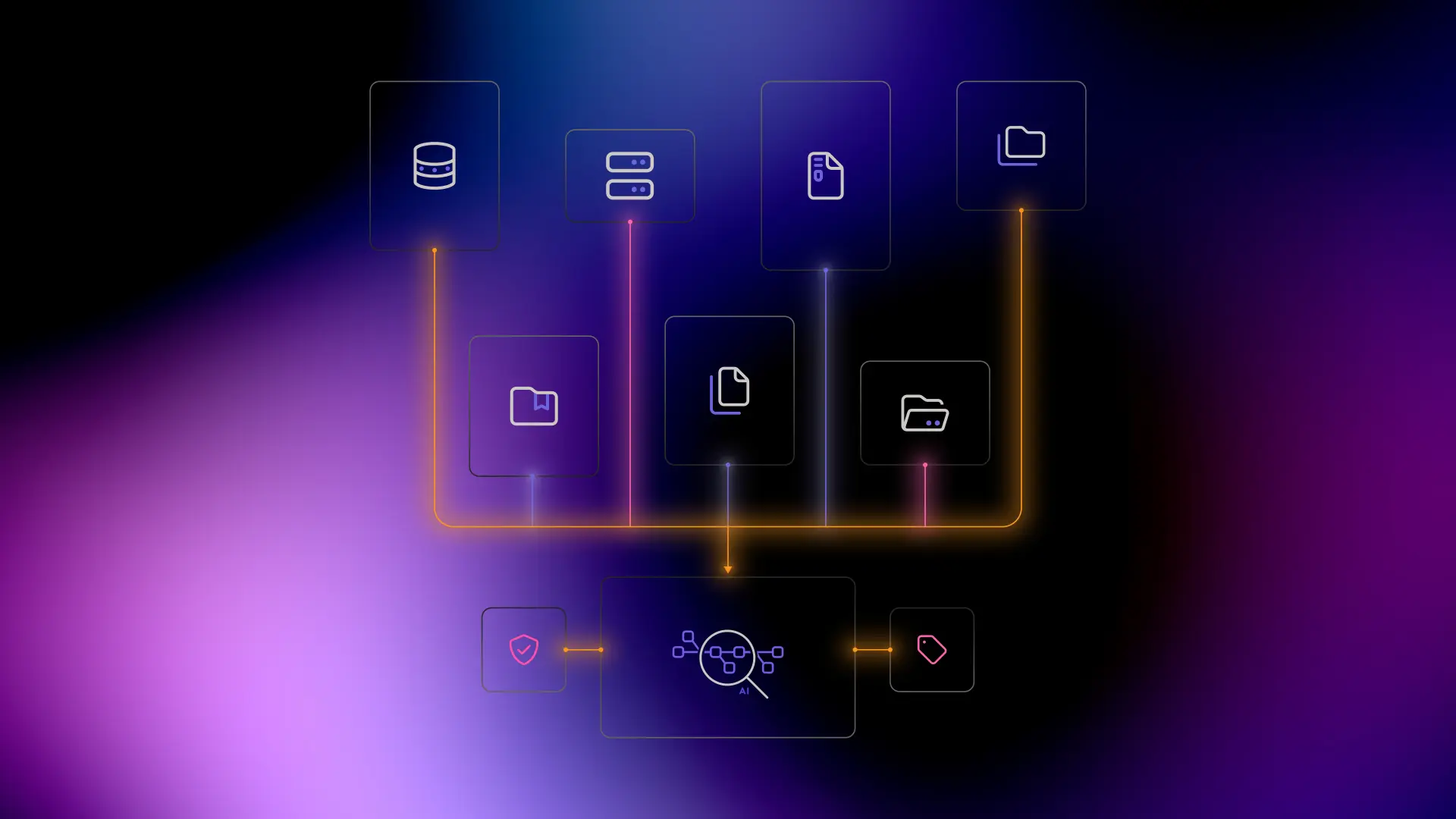
Unstructured data represents roughly 80% of enterprise information, yet most organizations have limited visibility into what this content contains or how it can be the value it can offer AI deployments.
By definition, unstructured data is information that does not fit into a predefined schema or table format, making it difficult to organize, query, or govern using traditional database tools. This covers essential documents such as contracts and manuals, communications including emails and chat logs, and rich media like images and videos. Much of this content sits siloed and scattered across platforms such as SharePoint, OneDrive, Box, local drives, and various departmental repositories, which makes it hard to access and even harder for AI systems to use.
Because it lacks structure, consistent tagging, and unified governance, unstructured content is harder to prepare for downstream analysis or automation, yet it contains the majority of an organization’s operational knowledge. This imbalance becomes especially relevant as enterprises shift toward AI systems that depend on language, context, and meaning.
Why unstructured data matters for AI
Unstructured data carries most of the real context inside an enterprise, which makes it essential for any AI system that aims to understand language, interpret nuance, and generate meaningful outputs. Conversely, structured data has been the backbone of enterprise analytics, and it is carefully cataloged, tagged, and checked for accuracy, making it reliable for dashboards, simulations, and machine learning models. However, structured datasets alone rarely provide the nuance and flexibility needed for AI driven applications. Large language models (LLMs) and other AI models are designed to work with natural language, free form text, and documents - the very types of data that most organizations have historically treated as secondary or supplementary.
Semantic search and reasoning capabilities in AI depend on context rich content. Without access to unstructured data, AI systems may struggle to generate accurate outputs or fully capture the knowledge embedded in an organization’s information. This explains why many enterprises have great AI ambitions but fail to deploy. Models and algorithms are only the first step, leveraging enterprise knowledge from unstructured data is critical to ensuring AI accuracy, context and relevancy.
The Barrier: Why unstructured data is hard to use
The biggest challenge to leveraging unstructured data for AI is simply enabling the AI to see it, understand it and control what it can do with it. This requires connection, access, structure and governance. Implementing this is challenging as files spread across shared drives, cloud repositories, and collaboration tools often end up duplicated, inconsistently named, lightly tagged, or missing ownership. Governance is also a struggle as these systems were designed for productivity and content creation, not data management. The result is a large and valuable body of information that is difficult to locate, interpret, or secure with the same discipline applied to structured datasets.
This fragmentation creates challenges for scaling AI. Individual teams may experiment with chatbots or recommendation engines, but without a unified approach to unstructured data, information remains siloed. AI models may be unable to access critical knowledge, resulting in incomplete, inconsistent, or inaccurate outputs.
Preparing unstructured data for AI
To make unstructured data usable for AI, the data needs to be transformed so it can be indexed, understood, and governed by downstream systems:
- Metadata tagging: assigning contextual labels to unstructured content improves discoverability and helps AI understand meaning.
- Connecting related information: linking documents, messages, and files through relationships or graphs provides missing context for AI reasoning.
- Secure, granular access: controlling who can access specific content, at the document or chunk level, ensures sensitive information is protected while enabling AI systems to work with authorized data.
Tools such as IndyKite Tags can provide a structured way to automate tagging and governance, which helps reduce the operational effort required to prepare content for AI systems. With this foundation in place, the same rigor used for structured data can be applied to unstructured information, turning it into a reliable base for AI native applications.
Scaling AI through unstructured data
Many AI experiments stall because they rely on small datasets or isolated tools. To scale effectively, organizations need a unified intelligence layer that connects structured and unstructured data across repositories, business units, and partner networks. Adding context and enforcing governance in real time ensures AI models retrieve accurate information securely and without delay. Operational visibility across contracts, policies, project files, customer interactions, and other sources allows AI systems to work from a complete, current view of enterprise knowledge, while fine-grained, context-aware policies ensure sensitive content is leveraged safely, supporting secure and scalable AI adoption.
The value of unstructured data for AI
When unstructured data is properly prepared - tagged, connected, and governed - it becomes a powerful asset. It enables AI models to work with a clearer view of the information that shapes decisions, and capabilities such as semantic search and contextual reasoning to operate on content that reflects how the organisation actually functions. As more of this material becomes accessible in a consistent and governed form, AI systems can deliver outputs that are reliable, auditable, and grounded in the full breadth of enterprise knowledge.
This shift turns unstructured content from an underused archive into a lasting competitive advantage.